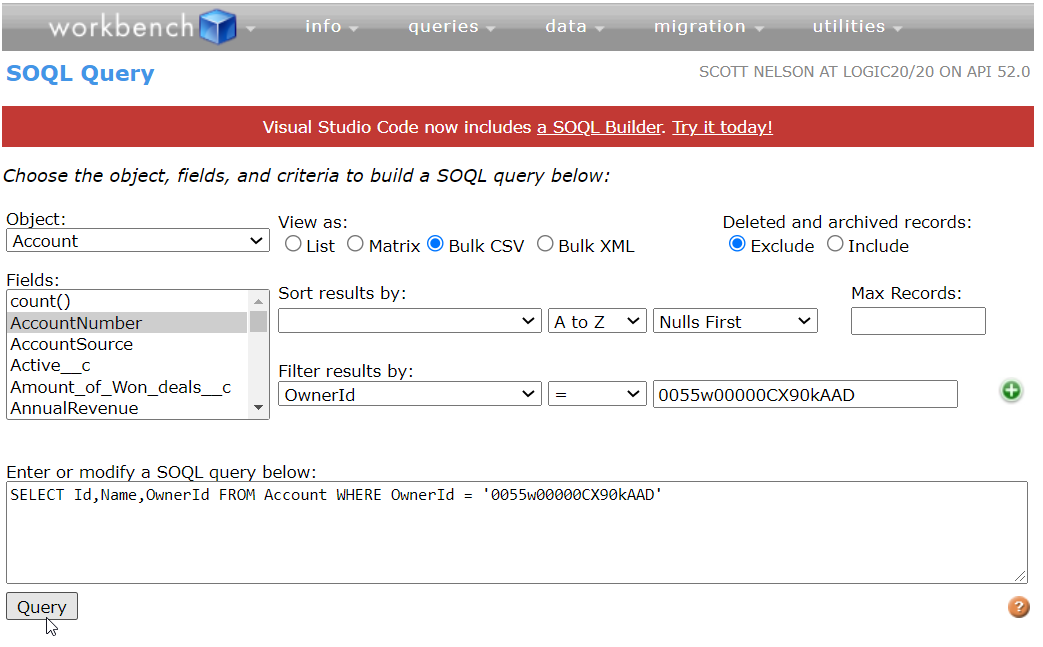
Quick summary: Technical debt is the elephant in the room … the same elephant that the blind men were curious about. Understand how perspective contributes to and can resolve tech debt.
Logic20/20 has been involved in many platform migrations and technology refreshes. While there are myriad reasons to make such a major shift, the three key drivers are:
- Gaining new capabilities
- Increasing time to market
- Reducing costs
Most other reasons will fit into one of those three, and usually it is more than just one of the three. All three are valid and valuable reasons to commit what is usually a large amount of resources to achieve. What is seldom acknowledged is that the initial motivation for the expense is to deal with technical debt.
Boom. Yes, that is a big statement. Let me unpack it a bit. Most new capabilities can be added through adapters or integration. Time to market can be severely hampered by technical debt, as can the costs associated with development and maintenance. That isn’t to say that upgrades and technology shifts aren’t necessary, only that the tipping point frequently comes from the accumulation of technical debt.
Once the transition to a new platform (be it an upgrade or vendor change) is complete, what follows depends on whether the influence of technical debt was acknowledged as part of the effort. Organizations that utilize processes, policies, and governance to manage technical debt can find that their ROI from the project will more than justify the expense. Those that do not recognize the contribution of technical debt to the problems with the old way of doing things and believe the issues were only within the platform will find that they will be ready for another migration in as little as one year.
The thing about technical debt is that it is not always recognized because of the different perspectives that result in its accumulation. I think of these as What, Why, and How. My experience is that the order of how these perspectives are realized determines the organization’s maturity in relation to managing technical debt. It is when they are recognized in the reverse order that it takes longer to reach a point where the organization is managing technical debt.

How is a technical aspect. It is the use of architecture, design, and implementation solutions that focused on the immediate need over the long-term solutions. At the time the decisions are made that lead to technical debt, the technical team usually knows it is happening and has hopes (if not actual expectations) to address the debt in later releases.
Why is a business problem, and is also more a series of questions than a statement. Was the initial debt incurred by informed decisions? Is the increasing debt the result of planned obsolescence or not knowing the impact? Are they even aware that their drive for business capabilities resulted in technical debt? The diagram at the end of Martin Fowler’s TechnicalDebtQuadrant post is the clearest representation of what leads to technical debt. Frequently the types of conversations necessary to make informed decisions don’t happen because technology and business make assumptions about viewpoints that are generally inaccurate. Communication is always a key factor to enterprise success.
What is a universal, once it is recognized either by the How or the Why: It is architecture and design issues that impede progress through time spent on maintenance and work-arounds. The How cannot change the What unless there is an important Why. In other words, the debt will not be reduced by technical teams unless there is a good reason for the business to pay for it.
The first step is reducing or eliminating the accumulation of technical debt. The second step is to determine how much focu$ will be dedicated to each release to reduce the technical debt. In most cases, this should be a gradual process of adopting new patterns and spending some time in each release refactoring what is related to the release. In some cases, the impact is so pervasive that either an entire release needs to be focused on refactoring or one team needs to be dedicated to it for one or more releases until is manageable again. Whereas most technical debt has a common cause, the path out of technical debt needs to be tailored to the enterprise and the system to be successful.
Originally publihsed at https://www.logic2020.com/insight/tactical/technical-debt-what-why-and-how
© Scott S. Nelson