One type of mapping I find particularly complicated to build is one using the SAP iDoc connector. The complicate part is achieving the correct value nesting. It is complicated because when you create the mapping, the nesting is not visible. It is created by the use of Primary and Foreign key fields (GPK and GFK in the mapplet).
I have seen several approaches to this that work and the approach I am going to share here is the one that I came up with and use because I understand it. YMMV.
First, I create a list of GPK and GFKs from the mapplet XML. These values can be found in the TRANFORMATION nodes within the MAPPLET node.
With this list in hand, I create the document GPK with a field that will be unique per iDoc. In this case I have a unique entity ID in my source and a date field that will make the entry for the entity unique. I prefix this key with the OTYPE because I may have multiple entries for the same object on the same date but different OTYPEs.
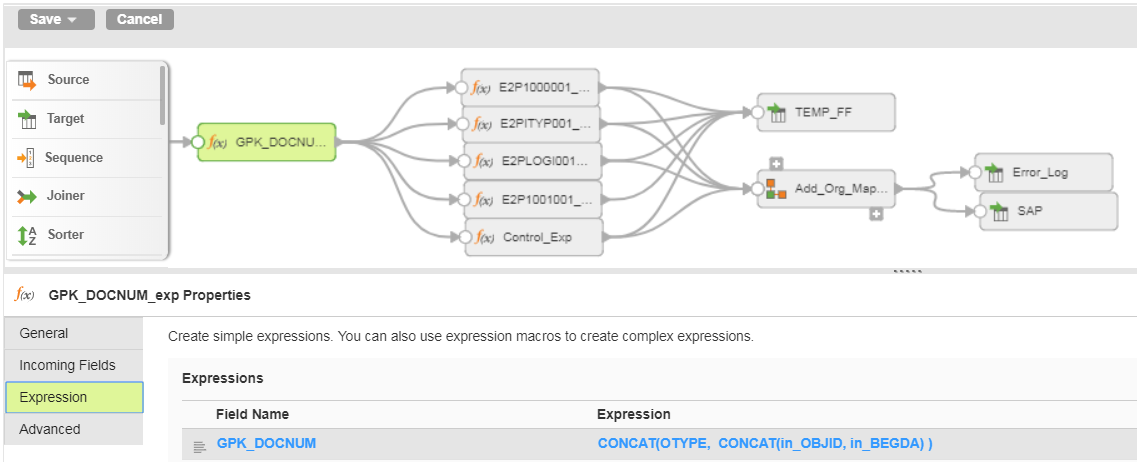
Then, for each immediate child, I define its GFK and GPK using the node names as prefixes:
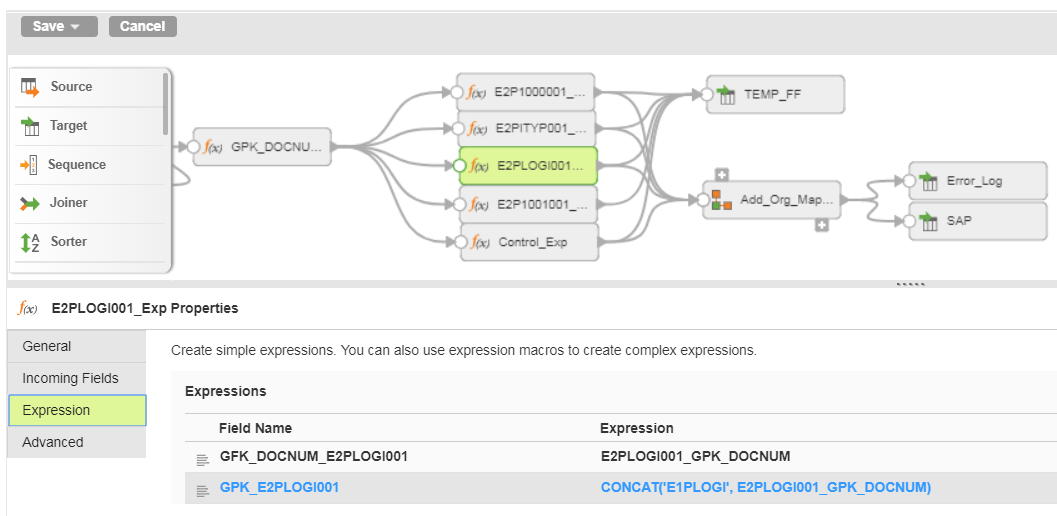
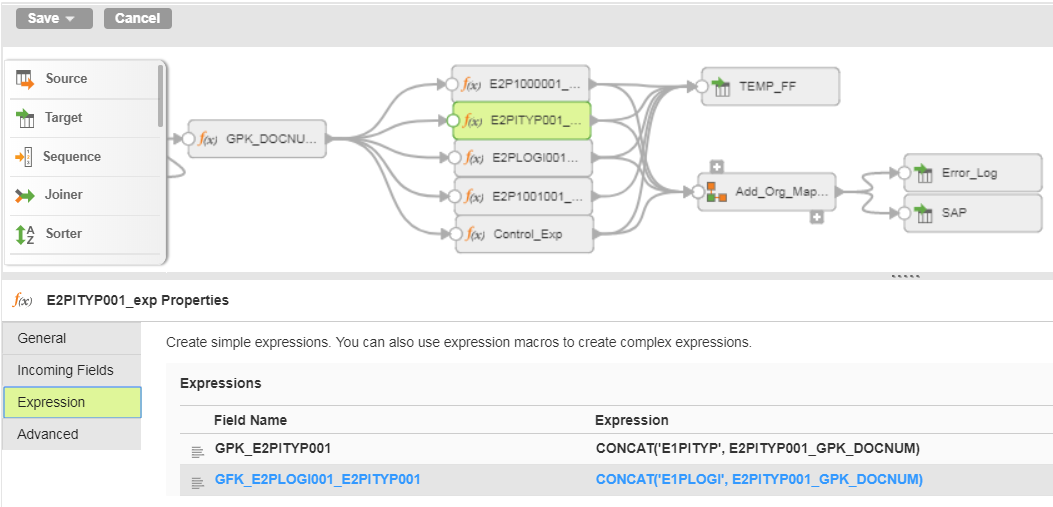
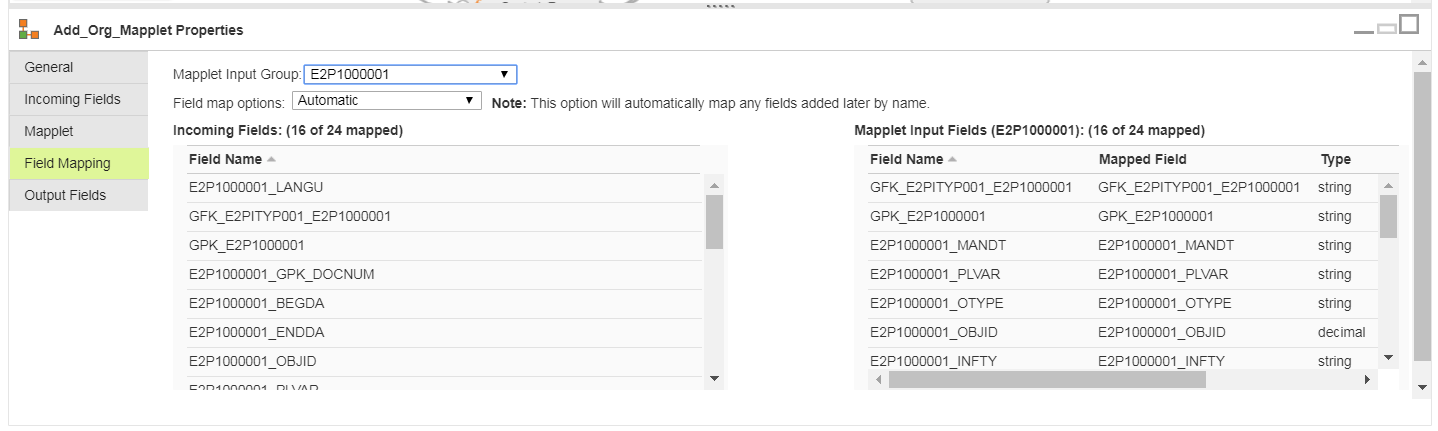
The above examples goes three levels deep. If your iDoc requires nest your nodes in a different pattern, generate your GPK values in such as way that they can be properly created in both the parent and child node.
For ease of maintenance, I name the fields in the expressions the same as they are defined in the mapplet so that I can use Automatic field mapping, which is eliminates the need to manually re-map anytime I make a change:
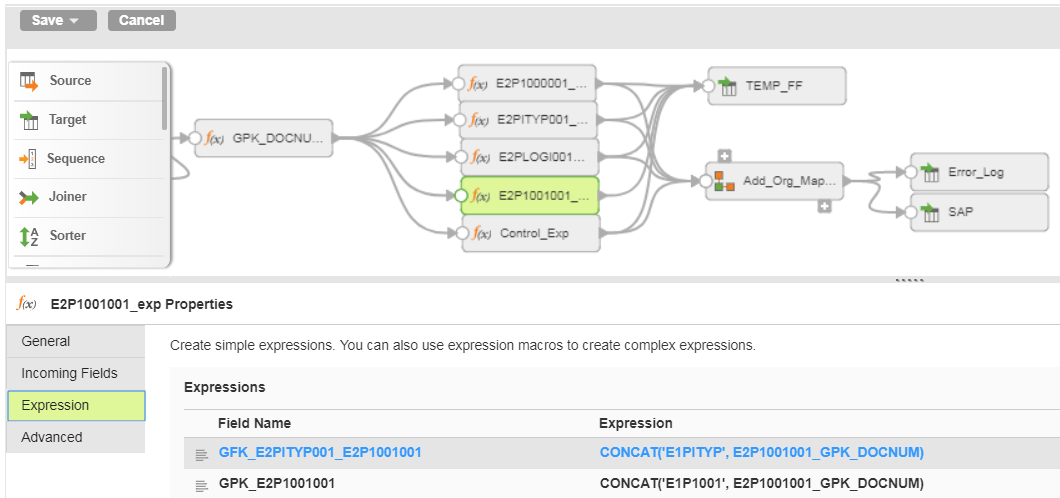
I hope this saves you some of the time it took to get me to this approach.
© Scott S. Nelson