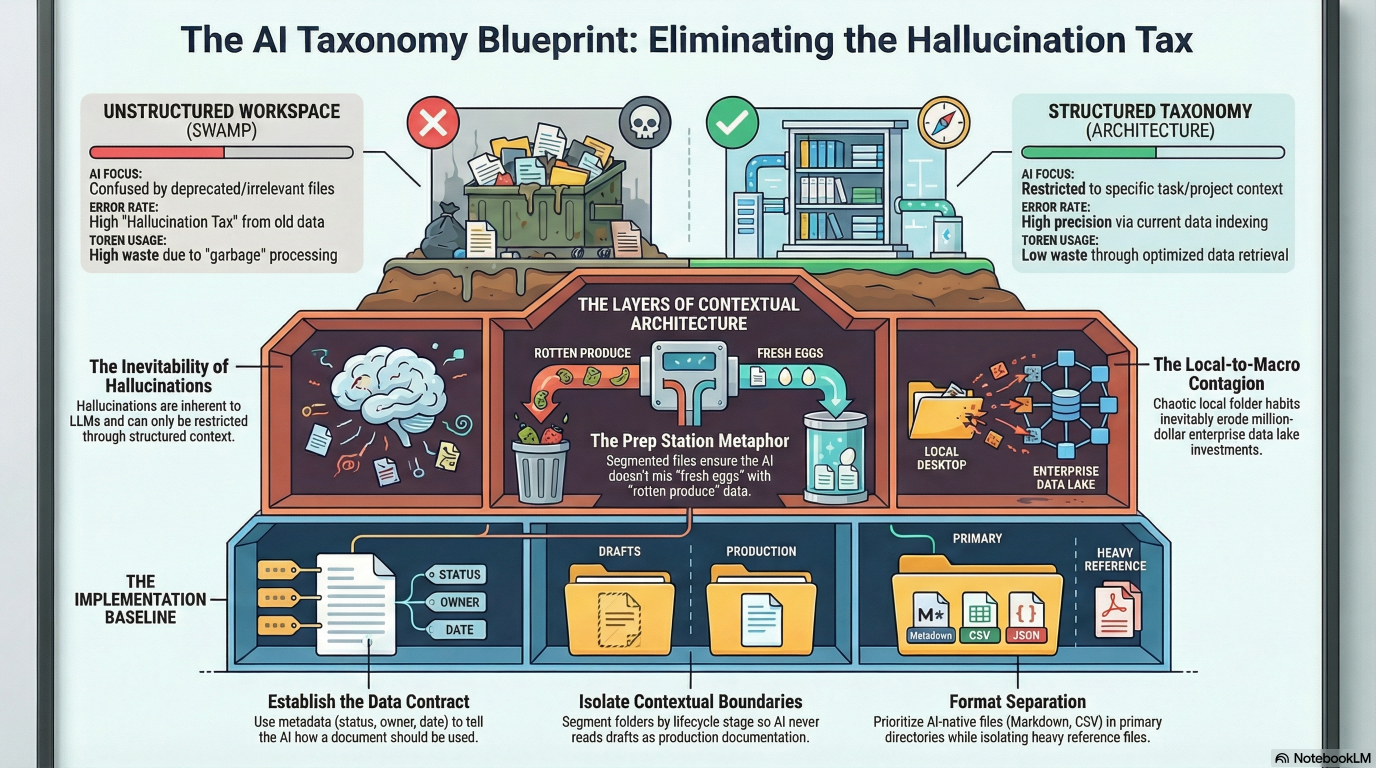
TL;DR: Your GenAI output is failing because your local workspace is a disaster. If your desktop is a dumping ground, your enterprise data lake is guaranteed to be a swamp. Stop blaming the model, establish a strict folder taxonomy, and kill the bad data habits before they scale.
For my regular reader, you know I can’t resist a pun, and the initial research note for this post was “Timely topic title: Take the Tax out of Taxonomy”. You also know I digress, so I thought I would get it out of the way at the start. Done. Moving on to the next level…
You are paying a massive hallucination tax. You bought a premium AI subscription or deployed a desktop agent. You pointed it at a project directory full of deprecated drafts, unstructured notes, “versioned” files, maybe even some sample code. Now the AI is confidently generating output based on requirements from three years ago, and maybe Wednesday’s lunch order.
The AI users assume a better foundation model or highly complex prompt engineering will fix output inaccuracy. They will not. According to the research paper A Comprehensive Taxonomy of Hallucinations in Large Language Models, hallucinations are not merely a bug, but a theoretically inevitable feature of computable LLMs, irrespective of architecture or training.
You cannot patch out hallucinations with a clever system prompt. You have to restrict their oxygen.
Generative AI operates entirely on the context it is fed. When you open a workspace (or upload a zip file, or point it at SharePoint), the model uses the folder structure to understand relationships. It assumes every file in the provided directory is equally valid, current, and relevant.
To get faster, accurate output, you must adopt a standardized, hierarchical folder taxonomy. This is not a housekeeping chore. It is a strict data contract for your AI. The academic consensus supports this structural approach. As outlined in A Systematic Framework for Enterprise Knowledge Retrieval, transforming a static blob of data into a navigable, context-rich knowledge architecture significantly improves model accuracy and reduces retrieval latency.
The Prep Station Metaphor
Think of an LLM as a highly skilled line cook with zero short-term memory. If you ask the cook to make an omelet, but point them to a kitchen counter where the fresh eggs are mixed in a pile with old receipts, bleach, and rotten produce, the resulting meal will be toxic.
You have to prep the station before you ask for the work.
This requires changing how you manage your local environments. You must segment your files and organize your folders explicitly by client, project, or (and sometimes “and”) specific activity. When the AI opens that specific folder, the taxonomy forces it to focus strictly on the given task.
The Micro-Macro Data Contagion
Local file structures often mirror enterprise data architecture. If your team’s shared drive is a chaotic dumping ground of nested, unnamed folders, your enterprise data lake is likely more of a content swamp.
Organizations often fund massive, top-down enterprise data transformation projects. They deploy tools to wrangle petabytes of unstructured data. Consultants are brought in to describe how it should be done, walk you through clean up, and leave you with a perfectly indexed wiki on how to maintain it.
The reason other organizations don’t do this kind of clean up? Aside from the few that don’t need it, the rest have someone recruited from an organization that did need it, then did it…then did it again a few years later. At least some had the excuse of acquisitions as a cause. The rest just forgot to make being organized part of the organization’s culture.
The report What Is Data Taxonomy? Use Cases & Best Practices points out that taxonomy programs do not fail because the classification structure was wrong. They fail because nobody owned it after launch, or the controlled vocabulary was written for data engineers rather than the business users who needed to adopt it. A taxonomy that nobody actively owns becomes outdated within twelve months.
If you build a pristine enterprise knowledge graph but your teams still save raw client notes to a local desktop folder named “Misc”, your clean data architecture will erode. Bad habits always defeat good infrastructure.
Start locally. Expand globally. Treat your team’s shared folder as the training ground for enterprise AI.
Here is the implementation baseline for engineering a reliable folder taxonomy.
- Force Local Discipline: The guide Document Taxonomy Simplified notes a critical reality: AI can read full text, but without consistent indexing and classification, it has a harder time understanding which documents are current or relevant for a specific question. Humans must define the taxonomy. Organizations that rely solely on AI risk amplifying bad data.
- Build a Strict Domain Hierarchy: Segment folders strictly by project and lifecycle status. Your AI should never have read access to a “Drafts” directory when you are asking it to write production documentation.
- Establish the Data Contract: Metadata like document type, owner, client, date, and status tells AI not just what a document says, but how it should be used. This context improves AI ranking and reduces irrelevant hits that happen to share keywords.
- Separate Human and AI-Native Formats: Segment your directories into files meant for humans and files meant for the AI. Lean towards using markdown files, text files, and CSV files for AI consumption. Keep heavy, formatting-rich files in a separate reference folder that the AI does not scan unless explicitly commanded.
- Isolate Contextual Boundaries: Open-ended prompts can generate answers that blend multiple disciplines or outdated content. When your library is indexed by department, project, and lifecycle stage, AI can narrow its focus and answer questions within the right slice of your information.
You’ll note that there is a lack of solid reference examples of good taxonomies. This is, again, related to data cleanliness being driven by culture. The same taxonomy may or may not work for another organization. But a solid taxonomy based on how the organization thinks and processes can easily be maintained through training, communication, and the occasional reminder (preferably automated).
The ROI of a strict folder taxonomy is immediate. Output precision goes up. Token waste goes down.
If your AI is only as reliable as the context it receives, your unstructured file storage is an active threat to your workflow. Build the hierarchy locally. Clean up the directories.
Credit to Dylan Davis‘s video 5 Changes That Make ChatGPT & Claude 10x Better for sparking this research.
