Most readers of this post will be too late to take the exam for free . . . which is why I am writing it.
I’ve been following the Salesforce Quests for years now. I first became aware of them when I would receive emails that they were ending with a week or less to finish them when they were always monthly and unique each month. When I had free time, I would jump in and finish them. Sometimes I would receive some merch several weeks later. Then I received a certification voucher when I only had one cert, and I tracked down the URL where the Quests are announced and set a monthly reminder to check for new ones. The Agentforce Specialist is my sixth certification, and I only paid for the first (technically, not even that one, as I talked my employer into allowing me to expense the exam). The rest I won vouchers for, with the exception of this one, which was free to everyone until the end of 2025.

I discovered the fact it was free while working through the Agentblazer series of badges. The final badge, Legend, requires certification and that is when I discovered it was free. The certification was free for quite some time, but my employer at the time did not get many Salesforce projects and I had missed the news. I discovered that it was free on October 10, and became determined to pass this one, too.
Even though I don’t get to work in the Salesforce ecosystem as much as I would like to, those monthly reminders to check out the latest Quests keep me involved in keeping up with the changes. So when I started on the Agentblazer series of badges, I already had some trails and modules under my belt, and quickly advanced to the Legend level where I learned of the free certification. Even so, I can honestly say that the Agentblazer Legend quest has been the most difficult I have worked through (disclaimer: at the time of this writing I have not completed the quest, but I will within a day or two . . . check my profile to keep me honest!) in almost a decade of questing.
But, truly, my core skill is digressing, and I have from the topic of getting certified, so back to it . . .
First, definitely earn the Agentblazer badges as a foundation. The path to earning them will prepare you for what comes next.
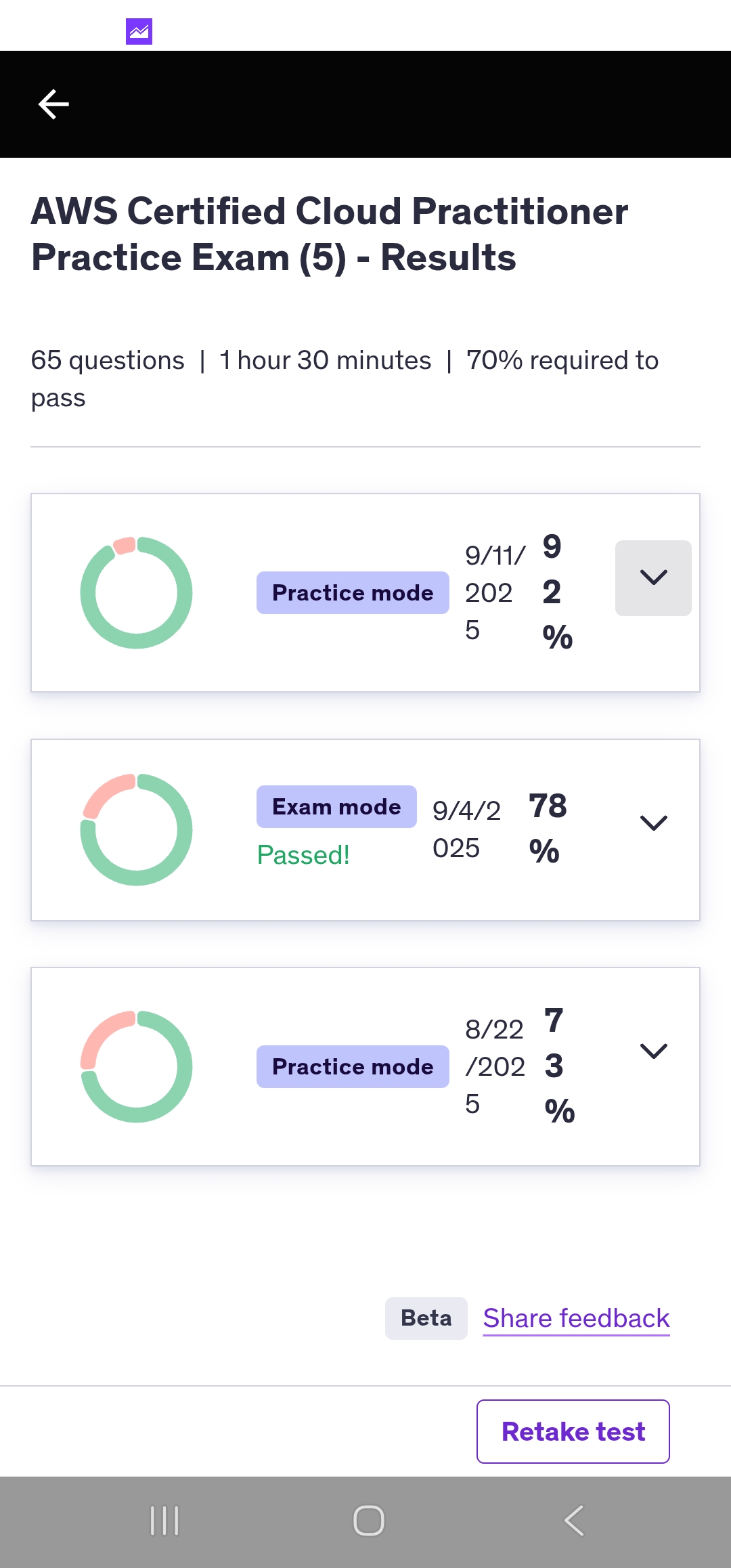
Which is, as I have always recommended for certification preparation, buy a pack of practice exams with as many quality questions as you can find and work your way through them. For this particular certification exam I used a Udemy course, Salesforce Certified Agentforce Specialist – Practice Exam (currently on sale for $9.99). One of my other blogs is “Cheap, Lazy Investor”, and to the cheap part, I did not buy any other practice exams because this one did the trick. It has 365 questions (not all unique) and they covered 95% of the concepts I found on the actual exam, so no complaints and some kudos.
Passing the exam requires a combination of rote knowledge and conceptual knowledge. Of the two, conceptual knowledge will bring the higher score. You can’t get by with just one. Rote knowledge is necessary for questions where there is clearly only one right answer. Conceptual knowledge is necessary to answer those questions where more than one answer is correct, because one answer is more correct than the other. The “more correct” is driven by understanding what is key to Salesforce and Agentforce. Concepts such as security, flexibility, and that the standard option is the best option if it meets all of the requirements. Use the practice exam to get examples.
Interestingly, while the value of LLMs is their ability to manage probabilistic responses, if one answer leans towards probabilistic and the other leans towards deterministic, the deterministic answer is most likely the correct one. Getting the most likely answer when your own knowledge isn’t helping is where conceptual knowledge is key.
The deployment lifecycle section of the exam focuses on what is specific to Agentforce. I had a really hard time getting NotebookLM to stick to that scope. After two failed attempts where it produced very detailed preparation around the full Salesforce Application Lifecycle Management, I finally created a new notebook, ran deep research specifically on deployment lifecycle processes and pitfalls related to Agentforce, then added my own missed questions and had it generate a note, which I then added as a source and ran the audio prompt again: “Focus only on making the contents of ‘Missed Practice Exam – Deployment Lifecycle.md’ thorough and memorable to the listener to ensure the reader can correctly answer all questions regarding the Agentforce deployment lifecycle questions in the Salesforce Agentforce Specialist certification exam. Avoid the use of emphatic expressions and emphatic modifiers. This is important.”
One important thing about practice exams: They are not the exam you will be taking. The value of reviewing the questions you missed is in identifying the concepts that are not solid in your thinking. This is one of the reasons why it isn’t too bothersome that NotebookLM goes outside the boundaries of provided content when generating the podcast audio. And don’t rely on NotebookLM to catch it all, either. If you miss the same question three times on a practice test, go read the material, re-do the Trailhead module, and create some Bionic notes on the topic. Sound like overkill? There is almost always some questions on the exam on topics not covered by the practice exams, so be fully prepared for those you can expect to answer will offset any score impact of topics that you never heard of until the exam.
I did not use Bionic notes this time. I still think it is a valuable technique.
If you’ve read my other certification articles, you will know that I use notes formatted as Bionic Reading® to review my notes on missed questions and key concepts. And that I sometimes use my own version, where I bold keywords rather than parts of words to get the concepts to stick. I stand behind this approach, but didn’t do much with it this time.
This time I used NotebookLM. I used advanced search to find links to content, plus links from the Trailhead content, and my own study notes exported as markdown from UpNote to create source content. Then I incrementally created generated AI audio content that I posted on YouTube and listened to continuously to drill the concepts into my head.
At the end of the day (or almost the end of the year), I passed the exam.
I also highly recommend the Salesforce Ben page for prep (and the site in general).
Good luck!
© Scott S. Nelson